Architecture
CloudSentinel is split into five loosely-coupled services that communicate over well-defined contracts (REST, gRPC, Prometheus). This page focuses on the agent — the component that does the actual chaos injection — because that is where most of the v0.2.0 work landed.
High-level diagram
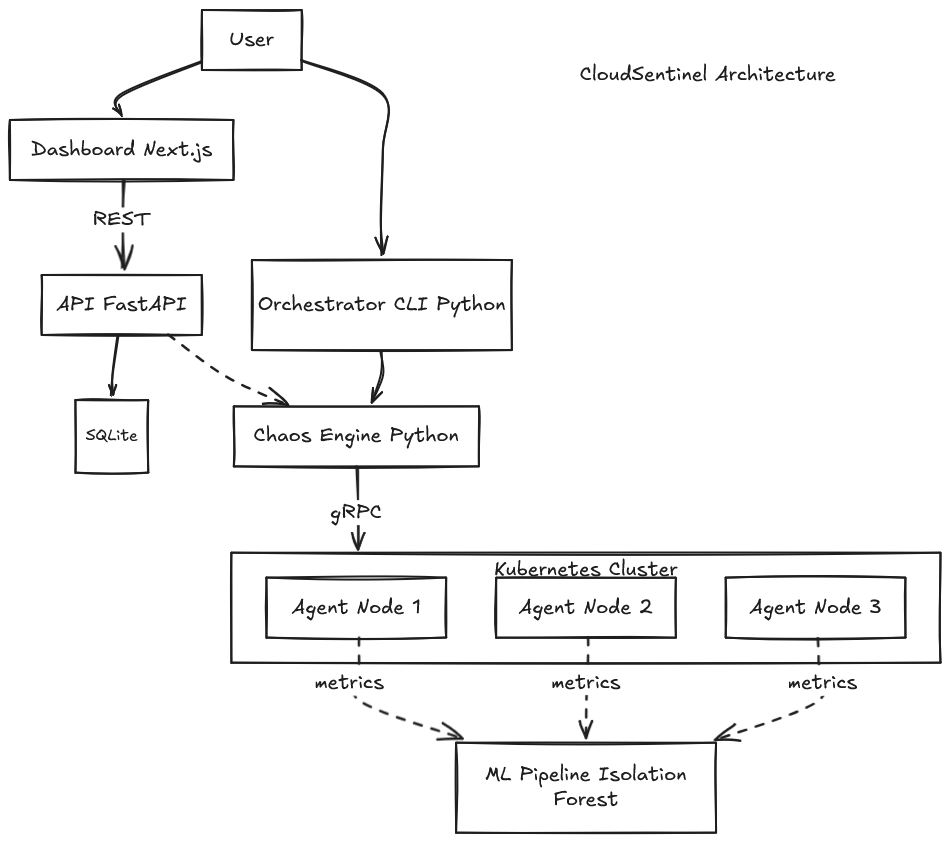
┌─────────────────────────────────────────────┐
│ USER (browser) │
└──────────────────┬──────────────────────────┘
│ HTTP
▼
┌─────────────────────────────────────────────┐
│ DASHBOARD (Next.js + Tailwind + shadcn/ui) │
│ - Lists scenarios with 5s polling │
│ - Create form in a Dialog │
│ - Per-row Run button │
└──────────────────┬──────────────────────────┘
│ REST (JSON)
▼
┌─────────────────────────────────────────────┐
│ API (FastAPI + SQLModel + SQLite) │
│ - GET/POST /scenarios │
│ - POST /scenarios/{id}/run │
│ - CORS for localhost:3000 │
└──────────────────┬──────────────────────────┘
│ orchestration
▼
┌─────────────────────────────────────────────┐
│ ORCHESTRATOR (Python CLI + chaos engine) │
│ - Provisions clusters via Terraform │
│ - Discovers agents through the K8s API │
│ - Speaks gRPC to each agent │
└──────────────────┬──────────────────────────┘
│ gRPC (protobuf)
▼
┌─────────────────────────────────────────────┐
│ AGENT Go (DaemonSet on every node) │
│ - HTTP :9100 /metrics (Prometheus) │
│ - gRPC :50051 InjectFault/Rollback/Status │
│ - Distroless image with tc (~56 MB) │
└─────────────────────────────────────────────┘
▲
│ scraped by Prometheus / fed to ML
│
┌─────────────────────────────────────────────┐
│ ML PIPELINE (scikit-learn Isolation Forest)│
│ - Trains on historical metrics │
│ - Classifies each observation normal/anom. │
└─────────────────────────────────────────────┘
Design principles
- Typed contracts everywhere. The Go agent exposes a
.protodefinition; Python and TypeScript clients are generated or mirrored from it. Pydantic schemas on the API mirror the Go messages. - Separation of concerns. The orchestrator never writes to the DB. The API never talks to Kubernetes. The agent does one thing: collect metrics and apply local faults.
- One image per service. Each service ships a multi-stage Dockerfile. The agent uses
gcr.io/distroless/base-debian12:nonrootfor a 56 MB attack surface. - Reproducible builds. Terraform modules,
poetry.lock,go.sum, andpackage-lock.jsonlock every dependency. CI re-runs the full test matrix on each push. - Test the behavior, not the return code. Every fault implementation is verified with measurements (
syscall.Getrusage,runtime.MemStats,os.Stat, mock executors).
Agent internals
The agent is the most interesting piece of CloudSentinel because it is where Linux internals, Go concurrency, and Kubernetes capabilities meet.
Strategy Pattern
The agent defines a Fault interface in internal/faults/fault.go:
type Fault interface {
ID() string
Type() string
Start(ctx context.Context) error
Stop(ctx context.Context) error
StartedAt() time.Time
Duration() time.Duration
}
Every fault type — CPUStress, MemoryPressure, DiskFill, NetworkLatency — has its own file in internal/faults/ and implements this interface. Adding a new fault type means writing one new file and adding one line to the dispatcher.
This is a textbook Strategy Pattern: the gRPC server treats every fault as a Fault, never as a concrete type, so the business logic stays decoupled from the implementation details.
Registry with auto-cleanup
internal/faults/registry.go is a thread-safe in-memory map of active faults, protected by a sync.Mutex. It exposes:
Add(ctx, fault)— start the fault, schedule atime.AfterFuncto callStopautomatically when the duration expiresStop(ctx, fault_id)— early rollback before the timer firesList()— snapshot of currently active faults (used byGetStatus)StopAll(ctx)— called onSIGTERMto clean up every fault before the process exits
The auto-cleanup via time.AfterFunc means the gRPC client does not need to stay connected — once the server accepts a fault, the rollback is guaranteed.
Thin gRPC server
internal/grpc/server.go is intentionally thin. It validates the request, picks the right Fault constructor, and delegates execution to the Registry:
func (s *Server) InjectFault(ctx context.Context, req *pb.InjectFaultRequest) (*pb.InjectFaultResponse, error) {
duration := time.Duration(req.DurationSeconds) * time.Second
params := faults.Params{Raw: req.Parameters}
fault, err := buildFault(req.Type, duration, params)
if err != nil {
return &pb.InjectFaultResponse{Accepted: false, Message: err.Error()}, nil
}
if err := s.registry.Add(ctx, fault); err != nil {
return &pb.InjectFaultResponse{Accepted: false, Message: err.Error()}, nil
}
return &pb.InjectFaultResponse{FaultId: fault.ID(), Accepted: true}, nil
}
All the Linux-specific logic is in internal/faults/, never in the gRPC layer.
How each fault works
| Fault | Mechanism | Verified by |
|---|---|---|
| CPUStress | N worker goroutines per logical CPU, each alternating a busy loop and a time.Sleep to match the configured intensity |
syscall.Getrusage measures consumed CPU-seconds |
| MemoryPressure | Allocates a []byte and starts a touch goroutine that writes one byte to every 4 KiB page every 200 ms (anti-swap) |
runtime.MemStats measures heap allocation |
| DiskFill | Writes 1 MiB chunks with non-zero bytes to a configured directory, then fsyncs |
os.Stat measures file size on disk |
| NetworkLatency | Calls tc qdisc add dev <iface> root netem delay <ms> on the node interface |
Mock TCExecutor verifies the exact arguments |
Mock TCExecutor
The network fault is the trickiest one because it needs tc and CAP_NET_ADMIN — neither of which is guaranteed in CI. The trick is to define an interface and inject the real implementation in production, a mock in tests:
type TCExecutor interface {
AddDelay(ctx context.Context, iface string, delay, jitter time.Duration) error
RemoveDelay(ctx context.Context, iface string) error
}
Production uses realTCExecutor which calls exec.CommandContext("tc", ...). Tests use mockTCExecutor which records the calls so the test can assert on the exact arguments. The result: 35 unit tests pass on any laptop, with no privileged operations.
This is a small idea but it is a real game-changer for testability.
Docker image
The agent ships as a three-stage Docker build:
# Stage 1: builder
FROM golang:1.24-alpine AS builder
RUN CGO_ENABLED=0 GOOS=linux go build \
-trimpath -ldflags="-s -w" \
-o /out/agent ./cmd/agent
# Stage 2: tc-stage
FROM debian:bookworm-slim AS tc-stage
RUN apt-get install -y --no-install-recommends iproute2
# Stage 3: runtime
FROM gcr.io/distroless/base-debian12:nonroot
COPY --from=builder /out/agent /agent
COPY --from=tc-stage /usr/sbin/tc /usr/sbin/tc
COPY --from=tc-stage /usr/lib/x86_64-linux-gnu/libbpf.so.1 ...
# (10 .so files copied)
ENTRYPOINT ["/agent"]
The result is a 56 MB image with:
- The
agentbinary, statically compiled with-trimpath - The
tcbinary plus 10 runtime libraries (libbpf,libelf,libmnl,libxtables,libz,libzstd,libcap,libbsd,libmd,libm) - A non-root user (UID/GID 65532)
- No shell, no package manager, no init system
You can verify locally:
docker run --rm --entrypoint /usr/sbin/tc cloudsentinel-agent:0.2.0 -V
# tc utility, iproute2-6.1.0, libbpf 1
DaemonSet hardening
agent/deploy/daemonset.yaml is the production reference manifest:
spec:
hostNetwork: true # tc rules on the node's interface
dnsPolicy: ClusterFirstWithHostNet # DNS still works
terminationGracePeriodSeconds: 30 # let Shutdown finish
initContainers:
- name: cleanup-orphans
image: registry.k8s.io/build-image/debian-iptables:bookworm-v1.0.0
command: ["/bin/sh", "-c", "tc qdisc del dev eth0 root 2>/dev/null || true"]
containers:
- name: agent
image: cloudsentinel-agent:0.2.0
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 65532
capabilities:
drop: [ALL]
add: [NET_ADMIN]
volumeMounts:
- name: fault-scratch
mountPath: /tmp/cloudsentinel-faults
volumes:
- name: fault-scratch
emptyDir: {}
Three things to notice:
hostNetwork: trueis required sotcrules apply to the node's real interfaces, not the pod's virtual one- The init container removes orphan
tcqdiscs left behind by a previous agent crash — best-effort, errors are silently ignored emptyDirat/tmp/cloudsentinel-faults/gives the disk fill fault a writable path even withreadOnlyRootFilesystem: true, and gets wiped on pod restart for free cleanup
Graceful shutdown
cmd/agent/main.go keeps a reference to the gRPC service implementation and calls csServer.Shutdown(ctx) inside the existing SIGINT/SIGTERM handler:
sigCh := make(chan os.Signal, 1)
signal.Notify(sigCh, syscall.SIGINT, syscall.SIGTERM)
<-sigCh
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
slog.Info("stopping active faults")
csServer.Shutdown(ctx) // iterate Registry, Stop every fault
grpcSrv.GracefulStop()
httpSrv.Shutdown(ctx)
Shutdown iterates the Registry and calls Fault.Stop(ctx) on every active fault: tc rules are removed, filler files are deleted, buffers are released, and CPU goroutines exit. The 10 second shutdown timeout is enough for all four implementations.
Combined with terminationGracePeriodSeconds: 30 on the DaemonSet, this means a node never stays in a chaos state by mistake.
Data flow — running a scenario
- User clicks Run in the dashboard
- The dashboard POSTs to
/scenarios/{id}/runon the API - The API reads the scenario from SQLite and records a
runningstatus - The API hands off to the orchestrator, which discovers matching agent pods and calls
InjectFaulton each - Each agent applies the fault locally and reports back synchronously
- When the fault duration expires, the agent's auto-cleanup kicks in. The orchestrator can also call
Rollbackearly on every agent it touched - The API transitions the scenario to
completed
The dashboard polls /scenarios every 5 seconds, so the status change surfaces in the table without a manual refresh.
Tests
| Suite | Count | Runtime |
|---|---|---|
Go — internal/faults |
21 tests | ~2s |
Go — internal/grpc |
8 tests | <1s |
| Python — orchestrator | 24 tests | ~1s |
| Python — API (FastAPI + SQLite) | 11 tests | <1s |
| Python — ML pipeline | 13 tests | ~2s |
| Total | 77 tests | ~6s |
Run everything with make test-all. Run just the agent suite with make test-agent.
Where to go next
- :material-gamepad-variant: Playground — try every fault type
- :material-brain: ML Pipeline — anomaly detection on collected metrics
- :material-source-branch: Source code on GitHub